from collections import Counter
import matplotlib.pyplot as plt
from nltk.tokenize import RegexpTokenizer
import pandas as pd
from pprint import pprint
import seaborn as sns
%matplotlib inline
A Presidential Debate in N-grams
While listening to the first presidential debate between Hillary Clinton and Donald Trump, I had a suspicion that a simple n-gram analysis would reveal some interesting insights into their respective styles of speech. So I grabbed a transcript off the internet (not the one here, but one like it) and got to n-gramming.
(N-grams are phrases of length n from a text or speech. When n is 2, it's called a bigram; when n is 3 it's called a trigram. We use the term n-gram because it generalizes to whichever N we want.)
with open("/data/data/sentiment/debate_transcript.txt", "r") as f:
all_lines = [line for line in f if line is not '\n']
What we get at the end of the function below is a list of 'tokens', or words, that a candidate has spoken. It takes care of a few formatting niceties: removing apostrophes so contractions are only one 'token', removing the candidates' names from their own speeches, changing the newline character to the word "NEWLINE", changing everything to lower case, and removing all punctuation.
def tokenize_by_user(line_list, identifying_string):
"""Reads in lines, filters based on the identifying string, and returns a list of tokens."""
speaker_lines = [line for line in line_list if identifying_string in line]
speaker_text = "".join(speaker_lines)
strings_to_drop = [identifying_string, "’"]
for element in strings_to_drop:
speaker_text = speaker_text.replace(element, "")
speaker_text = speaker_text.lower()
speaker_text = speaker_text.replace("\n", " NEWLINE ")
tokenizer = RegexpTokenizer(r'\w+')
speaker_tokens = tokenizer.tokenize(speaker_text)
return speaker_tokens
We need a list of tokens for both candidates.
trump_tokens = tokenize_by_user(all_lines, "Donald Trump:")
clinton_tokens = tokenize_by_user(all_lines, "Hillary Clinton:")
trump_counter = Counter(trump_tokens)
print("Total number of words spoken by Trump: {}".format(len(trump_tokens)))
print("Number of unique words spoken by Trump: {}".format(len(trump_counter.keys())))
print("Ratio of unique words to total words: {}".format(round(len(trump_counter.keys())/len(trump_tokens),3)))
print("\n")
clinton_counter = Counter(clinton_tokens)
print("Total number of words spoken by Clinton: {}".format(len(clinton_tokens)))
print("Number of unique words spoken by Clinton: {}".format(len(clinton_counter.keys())))
print("Ratio of unique words to total words: {}".format(round(len(clinton_counter.keys())/len(clinton_tokens),3)))
Total number of words spoken by Trump: 4153
Number of unique words spoken by Trump: 827
Ratio of unique words to total words: 0.199
Total number of words spoken by Clinton: 3099
Number of unique words spoken by Clinton: 843
Ratio of unique words to total words: 0.272
The disparity between their respective words spoken is sizable given the relatively tight structure of the debate. Mr. Trump seems to speak more quickly than Secretary Clinton, which is borne out in this dataset. The New York Times reports he spoke for 44:23 compared to her 41:21, so while he spoke for more time overall, he must speak more quickly as well.
pprint(trump_counter.most_common(20))
[('i', 137),
('NEWLINE', 136),
('the', 135),
('to', 129),
('and', 122),
('you', 111),
('that', 78),
('of', 74),
('a', 73),
('have', 71),
('it', 63),
('in', 40),
('we', 39),
('was', 38),
('its', 36),
('but', 36),
('very', 35),
('are', 34),
('not', 32),
('is', 32)]
pprint(clinton_counter.most_common(20))
[('the', 119),
('and', 106),
('NEWLINE', 97),
('to', 90),
('i', 84),
('that', 73),
('a', 67),
('of', 62),
('you', 46),
('in', 44),
('we', 43),
('it', 38),
('well', 34),
('have', 34),
('is', 33),
('be', 33),
('for', 28),
('think', 28),
('not', 24),
('about', 24)]
As would be expected, these lists are mostly dominated by stop-words. Mr. Trump's most commonly spoken word, 'I', is Secretary Clinton's fourth most commonly spoken.
trump_df = pd.DataFrame({'word':trump_tokens})
trump_df['wordlength']=trump_df['word'].apply(len)
clinton_df = pd.DataFrame({'word':clinton_tokens})
clinton_df['wordlength']=clinton_df['word'].apply(len)
trump_df['wordlength'].hist(bins=16, alpha=0.6, color='red')
plt.title("A histogram of Donald Trump's Word Lengths")
clinton_df['wordlength'].hist(bins=16, alpha=0.6, color='blue')
plt.title("A histogram of Word Lengths (colors are based on party lines)")
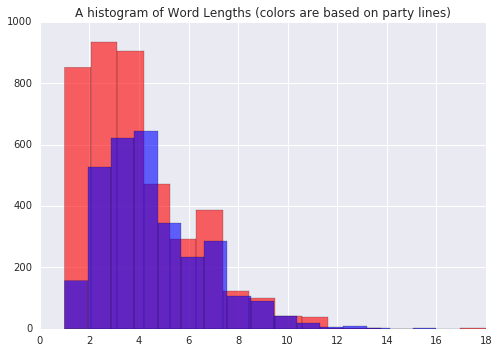
In general, Mr. Trump used shorter words than Secretary Clinton.
The n-grams part
What we wanted to know was whether there were phrases that popped up frequently for each candidate, so we analyzed for n=2...10 whether there were repeated phrases. My implementation is naive, as it considers the entire spoken corpus of each candidate as one document. The find_ngrams function is a nice little piece of code I found on Scott Triglia's blog.
def find_ngrams(input_list, n):
return zip(*[input_list[i:] for i in range(n)])
def print_ngrams(input_tokens, n_grams, candidate_name):
"""Starts with tokens and ends with only the top 15 n-grams that have been repeated
where available"""
print("{}'s {}-grams".format(candidate_name, n_grams))
found_ngrams = find_ngrams(input_tokens, n_grams)
ngramcount = Counter(found_ngrams)
repeat_keys = [key for key in ngramcount.keys() if ngramcount[key]>=2]
relevant_entries = sorted([[key, ngramcount[key]] for key in repeat_keys], key = lambda x: x[1], reverse=True)
print("{} {}-grams were repeated".format(len(relevant_entries),n_grams))
for entry in relevant_entries[:15]:
print("'{}' : {} times ".format(" ".join(entry[0]).replace("NEWLINE","-"), entry[1]))
#pprint(relevant_entries[:15])
print("\n")
return len(relevant_entries)
trump_repeats, clinton_repeats = {}, {}
for n_gram in range(2,10):
clinton_repeats[n_gram] = print_ngrams(clinton_tokens, n_gram, 'Hillary Clinton')
Hillary Clinton's 2-grams
326 2-grams were repeated
'i think' : 27 times
'- well' : 24 times
'you know' : 14 times
'and i' : 14 times
'to be' : 13 times
'a lot' : 11 times
'i have' : 11 times
'of the' : 10 times
'- and' : 10 times
'and the' : 10 times
'in the' : 10 times
'well i' : 8 times
'to do' : 8 times
'we need' : 8 times
'need to' : 8 times
Hillary Clinton's 3-grams
111 3-grams were repeated
'a lot of' : 7 times
'and i think' : 7 times
'- well i' : 7 times
'we need to' : 6 times
'we should be' : 4 times
'the middle class' : 4 times
'need to do' : 4 times
'well i think' : 4 times
'the united states' : 3 times
'- and i' : 3 times
'i think we' : 3 times
'to the debt' : 3 times
'of the united' : 3 times
'i wrote about' : 3 times
'what kind of' : 3 times
Hillary Clinton's 4-grams
32 4-grams were repeated
'we need to do' : 4 times
'- well i think' : 4 times
'taxes on the wealthy' : 3 times
'and i think its' : 3 times
'of the united states' : 3 times
'a lot - well' : 2 times
'and the kind of' : 2 times
'million people lost their' : 2 times
'- there are different' : 2 times
'i think we need' : 2 times
'5 trillion to the' : 2 times
'thats a lot of' : 2 times
'add 5 trillion to' : 2 times
'they dont give you' : 2 times
'and you know what' : 2 times
Hillary Clinton's 5-grams
8 5-grams were repeated
'add 5 trillion to the' : 2 times
'and i think its important' : 2 times
'would add 5 trillion to' : 2 times
'what i have proposed would' : 2 times
'different - there are different' : 2 times
'there are different - there' : 2 times
'5 trillion to the debt' : 2 times
'are different - there are' : 2 times
Hillary Clinton's 6-grams
4 6-grams were repeated
'there are different - there are' : 2 times
'would add 5 trillion to the' : 2 times
'are different - there are different' : 2 times
'add 5 trillion to the debt' : 2 times
Hillary Clinton's 7-grams
2 7-grams were repeated
'would add 5 trillion to the debt' : 2 times
'there are different - there are different' : 2 times
Hillary Clinton's 8-grams
0 8-grams were repeated
Hillary Clinton's 9-grams
0 9-grams were repeated
A few phrases seem notably rehearsed:
'taxes on the wealthy' : 3 times
'million people lost their' [jobs] : 2 times
'would add 5 trillion to the debt' : 2 times
Then there is the repeated phrase:
'there are different - there are different' : 2 times,
which may have come during an interruption. It's interesting to note that there are no 8 or 9-grams.
for n_gram in range(2,10):
trump_repeats[n_gram] = print_ngrams(trump_tokens, n_gram, 'Donald Trump')
Donald Trump's 2-grams
614 2-grams were repeated
'going to' : 23 times
'and i' : 18 times
'have to' : 16 times
'you have' : 16 times
'- well' : 14 times
'want to' : 14 times
'of the' : 14 times
'i was' : 13 times
'our country' : 12 times
'i dont' : 12 times
'- i' : 12 times
'tell you' : 11 times
'we have' : 11 times
'look at' : 11 times
'- and' : 11 times
Donald Trump's 3-grams
329 3-grams were repeated
'i want to' : 7 times
'you have to' : 6 times
'theyre going to' : 6 times
'you look at' : 6 times
'will tell you' : 5 times
'are going to' : 5 times
'law and order' : 5 times
'we have a' : 4 times
'the other day' : 4 times
'we need law' : 4 times
'you are going' : 4 times
'you want to' : 4 times
'because i want' : 4 times
'i will tell' : 4 times
'want to get' : 4 times
Donald Trump's 4-grams
153 4-grams were repeated
'need law and order' : 4 times
'you are going to' : 4 times
'we need law and' : 4 times
'to be able to' : 4 times
'because i want to' : 4 times
'want to get on' : 4 times
'to get on to' : 4 times
'i will tell you' : 4 times
'i want to get' : 4 times
'the kind of thinking' : 3 times
'let me tell you' : 3 times
'a great thing for' : 3 times
'president obamas fault -' : 3 times
'it president obamas fault' : 3 times
'you have to be' : 3 times
Donald Trump's 5-grams
77 5-grams were repeated
'we need law and order' : 4 times
'i want to get on' : 4 times
'because i want to get' : 4 times
'want to get on to' : 4 times
'of thinking that our country' : 3 times
'have to be able to' : 3 times
'thinking that our country needs' : 3 times
'the kind of thinking that' : 3 times
'i was against the war' : 3 times
'where did you find this' : 3 times
'is it president obamas fault' : 3 times
'you have to be able' : 3 times
'kind of thinking that our' : 3 times
'it president obamas fault -' : 3 times
'whether its the iran deal' : 2 times
Donald Trump's 6-grams
36 6-grams were repeated
'i want to get on to' : 4 times
'because i want to get on' : 4 times
'is it president obamas fault -' : 3 times
'kind of thinking that our country' : 3 times
'the kind of thinking that our' : 3 times
'of thinking that our country needs' : 3 times
'you have to be able to' : 3 times
'- where did you find this' : 2 times
'youre telling the enemy everything you' : 2 times
'they have to help us out' : 2 times
'enemy everything you want to do' : 2 times
'where did you find this -' : 2 times
'have to be able to negotiate' : 2 times
'she spent hundreds of millions of' : 2 times
'- you called it the gold' : 2 times
Donald Trump's 7-grams
14 7-grams were repeated
'because i want to get on to' : 4 times
'the kind of thinking that our country' : 3 times
'kind of thinking that our country needs' : 3 times
'spent hundreds of millions of dollars on' : 2 times
'telling the enemy everything you want to' : 2 times
'when i look at whats going on' : 2 times
'the enemy everything you want to do' : 2 times
'- you called it the gold standard' : 2 times
'i want to make america great again' : 2 times
'she spent hundreds of millions of dollars' : 2 times
'you have to be able to negotiate' : 2 times
'should have been doing this for years' : 2 times
'thats the kind of thinking that our' : 2 times
'youre telling the enemy everything you want' : 2 times
Donald Trump's 8-grams
5 8-grams were repeated
'the kind of thinking that our country needs' : 3 times
'youre telling the enemy everything you want to' : 2 times
'telling the enemy everything you want to do' : 2 times
'she spent hundreds of millions of dollars on' : 2 times
'thats the kind of thinking that our country' : 2 times
Donald Trump's 9-grams
2 9-grams were repeated
'youre telling the enemy everything you want to do' : 2 times
'thats the kind of thinking that our country needs' : 2 times
A few phrases seem notably rehearsed:
'we need law and order' : 4 times
'whether its the iran deal' : 2 times
'when i look at whats going on' : 2 times
'- you called it the gold standard' : 2 times
'i want to make america great again' : 2 times
'you have to be able to negotiate' : 2 times
'should have been doing this for years' : 2 times
'she spent hundreds of millions of dollars on' : 2 times
'youre telling the enemy everything you want to do' : 2 times
'thats the kind of thinking that our country needs' : 2 times
Mr. Trump had two repeated 9-grams, which are pretty sizable pieces of text. The last four n-grams all sound like they were soundbites that had been chosen specifically for this debate.
Finally, I thought it would be worth looking at the total number of n-grams for each speaker.
trump_repeat = pd.Series(trump_repeats)
trump_repeat = trump_repeat/(len(trump_tokens)/len(clinton_tokens))
trump_repeat.plot(kind='bar', color='red', alpha=0.7, title='Number of repeated n-grams for Donald Trump')
plt.ylim(0,500)
plt.show()
clinton_repeat = pd.Series(clinton_repeats)
clinton_repeat.plot(kind='bar', color='blue', alpha=0.7, title='Number of repeated n-grams for Hillary Clinton')
plt.ylim(0,500)
plt.show()
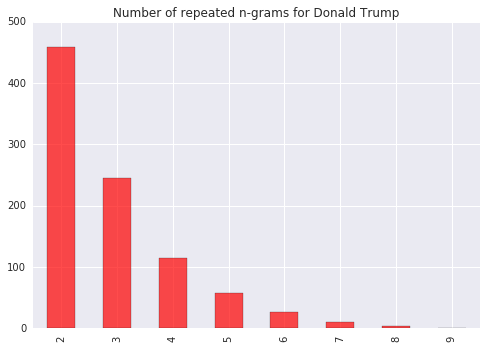
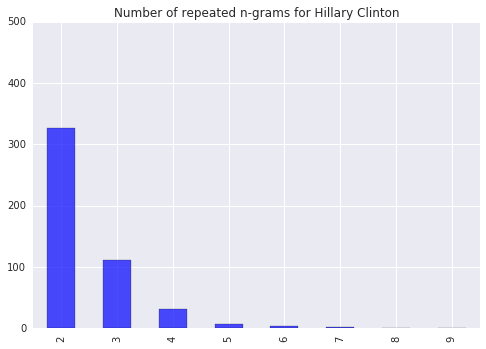
For the images above, I accounted for the difference in total words spoken between the two by scaling Mr. Trump's counts by the same factor his total tokens outnumbered Secretary Clinton's. It is immmediately clear that Mr. Trump had more repeated phrase chunks of every size.
Conclusions?
From this cursory n-gram-based method of analysis, it appears that Mr. Trump had more repeated phrases, even relatively longer phrases, than Secretary Clinton. One explanation could be that Mr. Trump's debate preparation may have emphasized word-for-word talking points more than Secretary Clinton's.